DACON - 집값 예측 경진대회
2022.01.24 ~ 2022.02.04 동안 진행되었던 DACON 집값 예측 경진대회에 참가 후기입니다.
Kaggle의 집 값 예측 데이터를 축소하여 가져온 듯합니다.
아래의 링크는 제가 작성한 코드를 DACON에 공유한 것입니다.
본 글에서는 데이터 분석 진행 과정을 요약해서 적어보려 합니다.
저번 펭귄 몸무게 예측 대회에 비해 결과가 좋지 않습니다. (public : 0.09942)
등수는 비밀입니다. 많이 아쉬운 결과라... 😐
정확히 어떤 부분에서 갈렸는지는 알 수 없지만 상위에 랭크되신 분들 코드를 참고해서 수정해봐야겠습니다.
해당 대회의 평가 산식은 'NMAE'였습니다.
▶ DACON 집값 예측 경진대회 - Code Share
EDA&Feature Engineering&Modeling(public : 0.09942)
집값 예측 경진대회
dacon.io

DataSet 확인
test, train data를 로드하고, 간단하게 확인했습니다.
df_train.shape
df_test.shape
df_train.info()
df_test.info()
EDA
개인적으로 EDA를 통해 insight를 얻고, Feature Engineering을 하는 것이 예측하는데에 있어 매우 중요하다고 생각합니다.
그래서 이번 대회도 EDA에 신경을 썼습니다.
EDA를 통해 진행한 과정들입니다.
이산형(Discrete Feature)과 연속형(Continuous Feature)로 분류했습니다.
Target 관련 코드만 첨부하겠습니다.
자세한 코드는 코드 공유나 깃헙을 참고하시길 바랍니다.
- target
- target
- 왼쪽으로 편향 → log transformation
- target
- Discrete Feature
- Overall Qual
- 값이 높을수록 집 값 높게 예측
- 개수가 30 이하인 범주는 병합 (근처 값에)
- Exter Qual
- Poor -> Fair -> Typical/Average -> Good -> Excellent
- 'Ex':1, 'Gd':0, 'TA':-1, 'Fa':-1, 'Po':-1로 mapping→ TA 아래 등급 항목들을 TA와 같다고 취급
- → TA 항목과 큰 차이가 없기 때문에 항목 개수를 줄여준다는 차원에서 두 항목을 병합
- Kitchen Qual
- mapping={'Ex':1, 'Gd':0, 'TA':-1, 'Fa':-1, 'Po':-1}
- Bsmt Qual
- mapping={'Ex':1, 'Gd':0, 'TA':-1, 'Fa':-1, 'Po':-1}
- Garage Cars
- 4,5는 3에 포함해서 생각
- → 수가 많지 않아서
- Full Bath
- 0 항목은 1 항목과, 2보다 큰 항목은 2 항목과 병합
- Overall Qual
- Continuous Feature
- Gr Liv Area
- 왼쪽으로 편향 → log transformation
- Garage Area
- 왼쪽으로 편향 → log transformation
- Total Bsmt SF
- 1st Flr SF
- → 왼쪽으로 편향 → log transformation
- Year Built
- Year Remod/Add
- Garage Yr Blt
- 2200 값 데이터 삭제 (잘 못 기입된 듯)
- Gr Liv Area
- Correlation 확인
import pandas_profiling
profile = df_train.profile_report()
profileplt.figure(figsize=(14,14))
plt.subplot(2,2,1)
plt.hist(df_train['target'])
plt.title('Histogram - target', fontdict={'fontsize':20})
plt.ylabel('Count')
plt.subplot(2,2,2)
plt.boxplot(df_train['target'])
plt.title('Boxplot - target', fontdict={'fontsize':20})
plt.subplot(2,2,3)
sns.kdeplot(df_train['target'])
plt.title('KDE - target', fontdict={'fontsize':20})
plt.subplot(2,2,4)
sns.distplot(df_train['target'],
color='b',
fit=stats.norm,
label='Skewness : {:.2f}'.format(df_train['target'].skew()))
plt.legend(loc='best')
plt.title('Distplot - target', fontdict={'fontsize':20})
plt.show()
# log transformation
plt.figure(figsize=(14,14))
plt.subplot(2,2,1)
plt.hist(np.log1p(df_train['target']))
plt.title('Histogram - target', fontdict={'fontsize':20})
plt.ylabel('Count')
plt.subplot(2,2,2)
plt.boxplot(np.log1p(df_train['target']))
plt.title('Boxplot - target', fontdict={'fontsize':20})
plt.subplot(2,2,3)
sns.kdeplot(np.log1p(df_train['target']))
plt.title('KDE - target', fontdict={'fontsize':20})
plt.subplot(2,2,4)
sns.distplot(np.log1p(df_train['target']),
color='b',
fit=stats.norm,
label='Skewness : {:.2f}'.format(np.log1p(df_train['target']).skew()))
plt.legend(loc='best')
plt.title('Distplot - target', fontdict={'fontsize':20})
plt.show()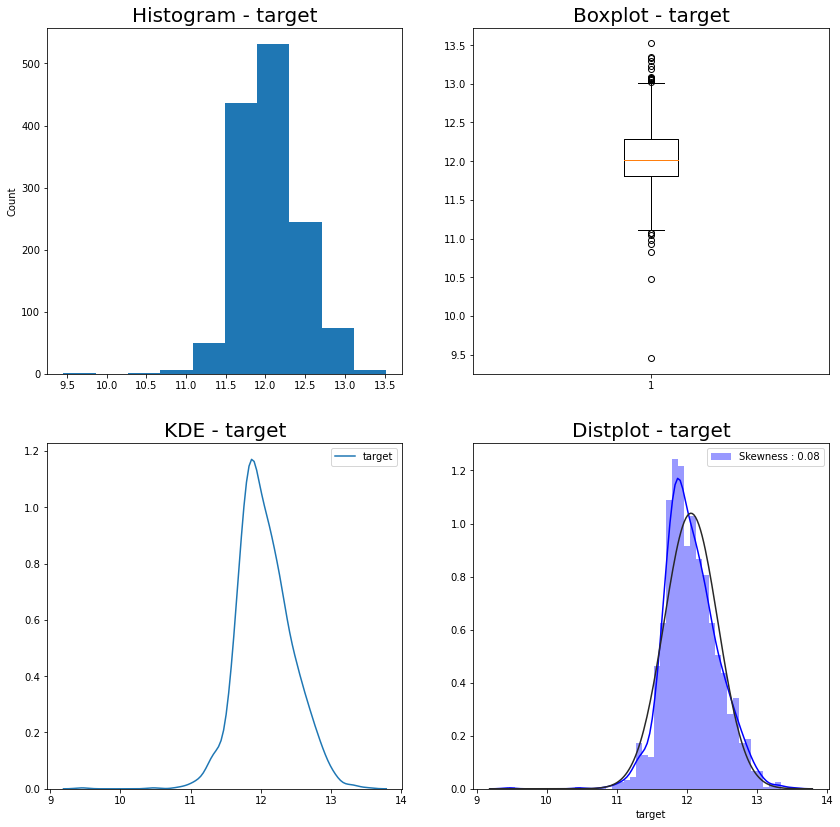
# 상관관계 분석도
plt.figure(figsize=(14,7))
heat_table = df_train.corr()
mask = np.zeros_like(heat_table)
mask[np.triu_indices_from(mask)] = True
heatmap_ax = sns.heatmap(heat_table, annot=True, mask=mask, cmap='coolwarm')
heatmap_ax.set_xticklabels(heatmap_ax.get_xticklabels(), fontsize=15, rotation=45)
heatmap_ax.set_yticklabels(heatmap_ax.get_yticklabels(), fontsize=15)
plt.title("correlation between features", fontsize=40)
plt.show()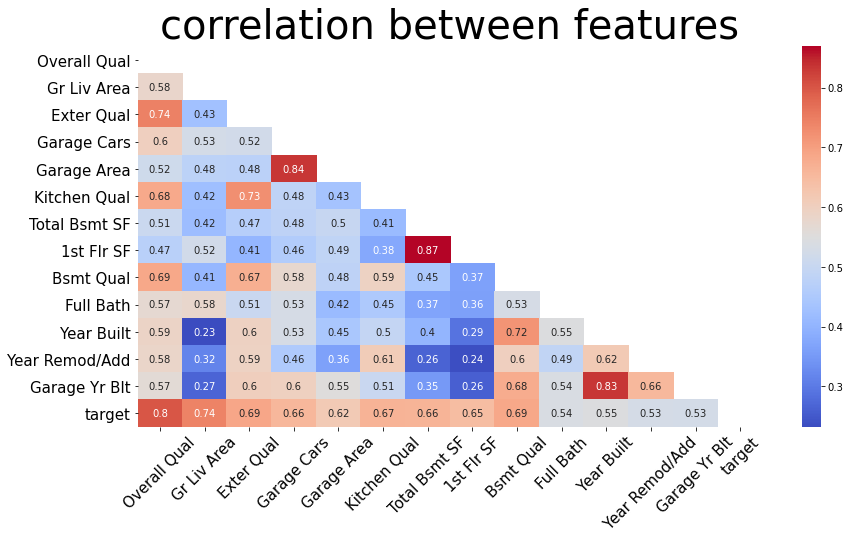
Feature Engineering
바로 전에 시행한 EDA를 통해 얻은 Insight를 통해 Feature Engineering을 진행했습니다.
상관관계와 Feature 특성을 통해 관련 있어 보이는 Feature들의 값과 관계를 살펴보고 피쳐 선택과 파생 변수를 추가했습니다.
피쳐끼리 상관계수가 높은 것들도 과적합을 방지하기 위해 피쳐 선택을 하였습니다.
- Outlier
- 데이터가 그렇게 많지 않다고 생각하여 이상치 제거 X
- Derived Variable (파생변수)
- Area
- 2층이상 층이 존재하는지 아닌지 Feature 생성
- Year
- 리모델링했는지 안 했는지 피쳐 추가
- 차고 고쳤는지 아닌지
- Area
- Feature Selection
- 상관관계 높은 피쳐 중 선택(제거) -> target과 상관계수 높은 거 살림
- Garage Cars 제거 (Garage Area 살림)
- Total Bsmt SF 제거 (1st Flr SF 살림)
- Garage Yr Blt 제거 (Year Built 살림)
- 상관관계 높은 피쳐 중 선택(제거) -> target과 상관계수 높은 거 살림
- Transformation (Log)
- target
- Gr Liv Area
- Garage Area
- 1st Flr SF
- One hot Encoding
- Standardization (표준화)
# 2층 이상 유무 Feature 생성
df_train['2nd Flr'] = np.where(df_train['Gr Liv Area'] > df_train['1st Flr SF'], 1, 0)
df_test['2nd Flr'] = np.where(df_test['Gr Liv Area'] > df_test['1st Flr SF'], 1, 0)
# 리모델링 했는지 안했는지 피쳐 추가
df_train['Remod'] = np.where(df_train['Year Built'] < df_train['Year Remod/Add'], 1, 0)
df_test['Remod'] = np.where(df_test['Year Built'] < df_test['Year Remod/Add'], 1, 0)
# 차고를 고쳤거나 최신이거나
df_train['Garage Remod'] = np.where(df_train['Year Built'] < df_train['Garage Yr Blt'], 1, 0)
df_test['Garage Remod'] = np.where(df_test['Year Built'] < df_test['Year Remod/Add'], 1, 0)# Feature Selection
df_train.drop(['Garage Cars', 'Total Bsmt SF', 'Garage Yr Blt'], axis=1, inplace=True)
df_test.drop(['Garage Cars', 'Total Bsmt SF', 'Garage Yr Blt'], axis=1, inplace=True)# Log Transformation
df_train['target'] = np.log1p(df_train['target'])
logtr = ['Gr Liv Area', 'Garage Area', '1st Flr SF']
for i in range(len(logtr)):
df_train[logtr[i]] = np.log1p(df_train[logtr[i]])
df_test[logtr[i]] = np.log1p(df_test[logtr[i]])# One-hot Encoding
df_train = pd.get_dummies(df_train, columns=['Exter Qual', 'Kitchen Qual', 'Bsmt Qual'])
df_test = pd.get_dummies(df_test, columns=['Exter Qual', 'Kitchen Qual', 'Bsmt Qual'])# Standardization
from sklearn.preprocessing import StandardScaler
scaled_col = ['Overall Qual', 'Gr Liv Area', 'Garage Area', '1st Flr SF', 'Year Built', 'Year Remod/Add']
scaler = StandardScaler()
df_train_scaler = scaler.fit_transform(df_train[scaled_col])
df_train[scaled_col] = pd.DataFrame(data=df_train_scaler, columns=scaled_col)
df_test_scaler = scaler.transform(df_test[scaled_col])
df_test[scaled_col] = pd.DataFrame(data=df_test_scaler, columns=scaled_col)
Modeling
최대한 아는 선에서 다양한 모델을 적용해보고 평가 산식인 MNAE로 모델 평가를 해서 모델을 선택하고 앙상블 하여 예측을 진행했습니다.
from sklearn.linear_model import LinearRegression, Ridge
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from xgboost import XGBRegressor
from lightgbm import LGBMRegressor
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import mean_absolute_error
def NMAE(true, pred):
mae = np.mean(np.abs(true-pred))
score = mae / np.mean(np.abs(true))
return score
X_data = df_train.drop('target', axis=1).values
target = df_train['target'].values
test_data = df_test.valuesX_train, X_test, y_train, y_test = train_test_split(X_data, target, test_size=0.3, random_state=0)
lr_reg = LinearRegression()
rg_reg = Ridge()
rf_reg = RandomForestRegressor(random_state=0, n_estimators=1000)
gb_reg = GradientBoostingRegressor(random_state=0, n_estimators=1000)
dt_reg = DecisionTreeRegressor(random_state=0, max_depth=4)
xgb_reg = XGBRegressor(n_estimators=1000)
lgb_reg = LGBMRegressor(n_estimators=1000)
lr_reg.fit(X_train,y_train)
rg_reg.fit(X_train,y_train)
dt_reg.fit(X_train,y_train)
rf_reg.fit(X_train,y_train)
gb_reg.fit(X_train,y_train)
xgb_reg.fit(X_train,y_train)
lgb_reg.fit(X_train,y_train)
y_preds_lr = lr_reg.predict(X_test)
y_preds_rg = rg_reg.predict(X_test)
y_preds_dt = dt_reg.predict(X_test)
y_preds_rf = rf_reg.predict(X_test)
y_preds_gb = gb_reg.predict(X_test)
y_preds_xgb = xgb_reg.predict(X_test)
y_preds_lgb = lgb_reg.predict(X_test)result = {}
result['score_lr'] = NMAE(y_test, y_preds_lr)
result['score_rg'] = NMAE(y_test, y_preds_rg)
result['score_dt'] = NMAE(y_test, y_preds_dt)
result['score_rf'] = NMAE(y_test, y_preds_rf)
result['score_gb'] = NMAE(y_test, y_preds_gb)
result['score_xgb'] = NMAE(y_test, y_preds_xgb)
result['score_lgb'] = NMAE(y_test, y_preds_lgb)
pd.options.display.float_format = '{:.5f}'.format
pd.DataFrame(result.values(), index=result.keys()).rename(columns={0:'NMAE'})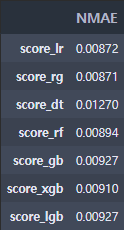
Prediction & Submission
NMAE이 낮은 Ridge, RandomForestRegressor를 사용하여 예측하고 앙상블을 진행했습니다.
rg_reg = Ridge()
rf_reg = RandomForestRegressor(random_state=0, n_estimators=1000)
rg_reg.fit(X_data,target)
rf_reg.fit(X_data,target)
y_preds_rg = rg_reg.predict(test_data)
y_preds_rf = rf_reg.predict(test_data)pred_ensemble = np.expm1((y_preds_rg+y_preds_rf) / 2)
# submission
submission_ensemble = pd.read_csv('./data/sample_submission.csv')
submission_ensemble['target'] = pred_ensemble
submission_ensemble.to_csv("./data/submission_ensemble.csv", index=False)
Reference
집값 예측 경진대회 - DACON
좋아요는 1분 내에 한 번만 클릭 할 수 있습니다.
dacon.io
▶ https://github.com/Park-taenam/DACON/tree/main/HousePrices
GitHub - Park-taenam/DACON: DACON Competition
DACON Competition. Contribute to Park-taenam/DACON development by creating an account on GitHub.
github.com
'Etc > Kaggle & DACON' 카테고리의 다른 글
| [DACON] 항공사 고객 만족도 예측 경진대회 (0) | 2022.02.17 |
|---|---|
| [DACON] 펭귄 몸무게 예측 경진대회 (0) | 2022.01.11 |
| [Kaggle] Titanic 필사 - 이유한님 (0) | 2022.01.09 |



댓글