목차
결정 트리 (Decision Tree)
- 분류와 회귀 작업 그리고 다중 출력 작업도 가능한 다재다능한 머신러닝 알고리즘
- 분류 : 목표변수가 범주형인 경우
- 회귀 : 목표변수가 연속형인 경우
- 지도 학습 알고리즘에 해당
- 매우 복잡한 데이터셋도 학습할 수 있는 강력한 알고리즘
- 의사결정 나무 방식의 최대 장점은 데이터 전처리 불필요 → 특성의 스케일을 맞추거나 평균을 원점에 맞추는 작업 등이 필요하지 않음.
결정 트리 학습과 시각화, 예측
사이킷런(scikit-learn) - tree.DecisionTreeClassifier
from sklearn.datasets import load_iris
from sklearn import tree
iris = load_iris()
X, y = iris.data, iris.target
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)import graphviz
dot_data = tree.export_graphviz(clf, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("iris")
dot_data = tree.export_graphviz(clf, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
graph
- petal length (cm) <= 2.45 : True면 왼쪽 자식 노드로, False면 오른쪽 자식 노드로
- gini : 지니 점수(불순도)
- samples : 해당 마디 결정에 사용된 샘플 수
- value : 해당 마디 결정에 사용된 샘플을 클래스 별로 구분한 결과. 훈련 샘플의 레이블 정보를 이용하여 분류.
- class : 각 클래스별 비율을 계산하여 가장 높은 비율에 해당하는 클래스 선정. 동일한 비율이면 낮은 인덱스 선정.
tree_clf.predict_proba([[5, 1.5]]) # 클래스에 속할 확률 출력
tree_clf.predict([[5, 1.5]]) # 클래스 예측값 출력
관련 용어
- 마디 (node) : 가지치기가 시작되는 지점
- 뿌리 마디(root node) : 맨 위의 마디
- 중간 마디 : 중간에 있는 끝마디가 아닌 마디
- 끝마디(잎 마디) (leaf node) : 각 줄기의 맨 끝에 위치한 마디
- 자식 마디 : 하나의 마디로부터 분리되어 나간 마디
- 부모 마디 : 자식 마디의 상위 마디
- 순수 노드 : 불순도 = 0
※ 부모 마디와 자식 마디는 상대적 개념
- 깊이 (depth) : 가지를 이루고 있는 마디의 개수
- 불순도 (Impurity) : 다른 class의 개체들이 얼마나 많이 포함되어있는지 표현
- gini (지니 불순도)
- criterion="gini”
- 지니 지수가 낮을수록 불순도도 낮음
- gini=0 : 순수
- Entropy (엔트로피)
- criterion="entropy”
- 분자의 무질서함을 측정하는 것으로 원래 열역학의 개념
- 엔트로피 = 0 : 한 클래스의 샘플만 담고 있다면
- gini (지니 불순도)
정보획득 (Information Gain) : 얼마나 불순도가 감소했는지 나타냄 (사전 Entropy - 사후 Entropy)
두 불순도의 차이는 크지 않으며, 비슷한 의사결정 나무를 생성
반면에 엔트로피 불순도가 좀 더 균형 잡힌 이진 나무(balanced binary tree)를 생성
지니 불순도가 좀 더 계산이 빠르기에, 기본값으로 사용
DecisionTreeClasifier의 default criterion = “gini”
DecisionTreeRegressor의 default criterion = “mse”
CART 훈련 알고리즘
사이킷런은 결정 트리를 훈련시키기 위해 CART 알고리즘 사용
CART (Classification and regression tree)
- 먼저 훈련 세트를 하나의 특성 k 의 임곗값 t_k를 사용해 두 개의 서브셋으로 나눔(예를 들면 꽃잎의 길이 ≤ 2.45cm )
- (크기에 따른 가중치가 적용된 ) 가장 순수한 서브셋으로 나눌 수 있는 (k, t_k ) 짝을 찾음.
- CART 알고리즘이 훈련 세트를 성공적으로 둘로 나누었다면 같은 방식으로 서브셋을 또 나누고 반복.
- 이러한 과정은 최대 깊이가 되면 중지하거나 불순도를 줄이는 분할을 찾을 수 없을 때 멈춤.
※ 리프 노드 외의 모든 노드는 자식 노드를 두 개씩 가짐 “Ture” or “False”
※ 다른 몇 개의 매개변수도 중지 조건에 관여
→ 알고리즘이 최소화해야 하는 비용 함수
CART 알고리즘은 탐욕적 알고리즘이다.
현재 단계의 분할이 몇 단계를 거쳐 가장 낮은 불순도로 이어질 수 있을지 없을지는 고려 X
→ 탐욕적 알고리즘은 종종 납득할만한 훌륭한 솔루션을 만들어내지만 최적의 솔루션을 보장하지는 않음.
→ 납득할 만한 좋은 솔루션으로만 만족
규제 매개변수
결정 트리는 훈련 데이터에 대한 제약 사항이 거의 없음
제한을 두지 않으면 트리가 훈련 데이터에 아주 가깝게 맞추려고 해서 대부분 과대 적합되기 쉬움
비파라미터 모델 vs 파라미터 모델
- 비파라미터 모델 (nonparametric model)
- 훈련되기 전에 파라미터 수가 결정되지 않음
- 과대 적합 위험 높음
- 파라미터 모델 (parametric model)
- 미리 정의된 모델 파라미터 사용
- 과대적합 위험도 줄어듦
- 과소 적합 위험도 커짐
규제
훈련 데이터에 대한 과대 적합을 피하기 위해 학습할 때 결정 트리의 자유도를 제한
- max_depth : 결정 트리의 최대 깊이 제어
- default : None
- min _samples_split : 분할되기 위해 노드가 가져야 하는 최소 샘플 수
- min_samples_leaf : 리프 노드가 가지고 있어야 할 최소 샘플 수
- min_weight_fraction_leaf : 가중치가 부여된 전체 샘플 수에서의 비율
- min_sample_leaf와 동일
- max_leaf_nodes : 리프 노드의 최대 수
- max_features : 각 노드에서 분할에 사용할 특성의 최대 수
규제를 높이는 법
min_ : 규제 값을 키움
max_ : 규제 값을 줄임
회귀
사이킷런(scikit-learn) - tree.DecisionTreeRegressor
분류 트리와의 차이
- 각 노드에서 클래스를 예측하는 대신 어떤 값을 예측
- 각 영역의 예측값은 항상 그 영역에 있는 타깃 값의 평균
- 알고리즘은 예측값과 가능한 한 많은 샘플이 가까이 있도록 영역을 분할
- 평균제곱오차(MSE)를 최소화하도록 분할
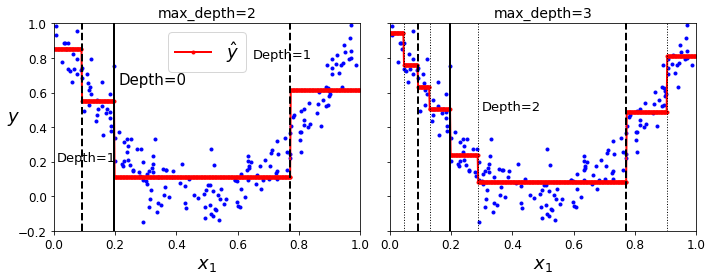
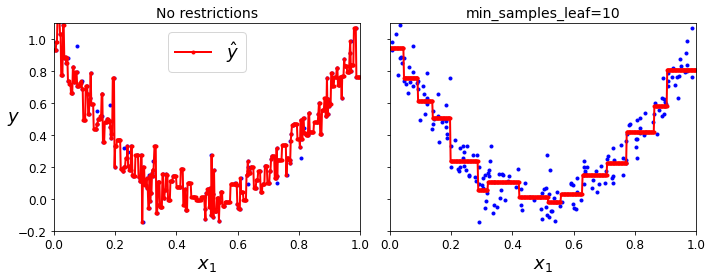
장단점
장점
- 해석의 용이성
- 직관적인 이해와 해석 가능
- 비모수적 모형
- 통계 모델에 요구되는 여러 가정(정규성, 독립성, 등분산성 등)에 자유로움
- 순위만 분석에 영향을 미치기 때문에 이상치에 크게 영향받지 않음
- 변수 간 상호작용
단점
- 훈련 데이터에 있는 작은 변화에도 매우 민감.
- 이상치 제거 등 작은 변화에 매우 민감함.
- 불안정성
- 훈련 데이터 수가 적을 경우 불안정할 수 있으며, 과대 적합될 위험이 높음.
- 불연속성
- 연속형 변수를 구간화 시키기 때문에 경계가 되는 지점에서 오차가 생길 수 있음
- 회전에 민감
- 결정 트리는 계단 모양의 결정 경계를 만듦
- (모든 분할은 축에 수직)
Reference
- 핸즈온 머신러닝 - 6장 (결정 트리)
- 결정 트리와 불순도에 대한 궁금증
결정 트리와 불순도에 대한 궁금증
이 글은 세바스찬 라쉬카의 머신러닝 FAQ 글(Why are implementations of decision tree algorithms usually binary and what are the advantages of the different impurity metrics?)을 번역한 것입니다. 결정 트리 알고리즘은 왜 이진
tensorflow.blog
1.10. Decision Trees
Decision Trees (DTs) are a non-parametric supervised learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by learning s...
scikit-learn.org
Entropy, Information gain and Gini Index; the crux of a Decision Tree
A brief on the key information measures used in a decision tree algorithm.
blog.clairvoyantsoft.com
'Data Science > Machine Learning' 카테고리의 다른 글
| [ML] Clustering (군집화) - K-Means, Hierarchical Clustering (0) | 2022.06.29 |
|---|---|
| [ML] 회귀 (Regression)와 경사하강법 (Gradient descent) (0) | 2022.02.22 |
| [ML] 분류(Classification) (2) | 2022.02.06 |
| [ML] 머신러닝(Machine Learning)이란? (0) | 2022.02.06 |




댓글